Wrangling and Analysis
![]()
In this section, we will clean, join perform some basic analysis on the data to answer a few questions. Let's import a few libraries we will require.
1 2 3 4 5 6 7 8 | |
Now let's read the infoboxes.json file we exported from Section 3 to a dictionary as follows,
1 2 3 4 | |
1 | |
1 2 | |
and have a quick glance at the first element of the same,
1 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
As evident from above, we can see that the data is in quite a messy format. For this excercise, we will primarily focus on the following attributes :
productsindustriesandassets
and try to answer a few questions using the data.
What type of products are sold by the top 20 companies?¶
Looking at a sample for products,
1 2 3 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
We can observe that we need to :
- Extract only the products from between
{{and}}or[[and]], and - Only keep alphanumeric characters,
-and preserve the spaces between
Let's define a regular expressions to clean and extract the products from the dictionary.
1 | |
Regex breakdown :
\w: Indicates alphanumeric characters i.e.a-z,A-zand0-9\s: Indicates a space[..]: Captures a single instance of the above (a single letter or number)+: Captures one or more of the above
Note:
\is used for escaping and to avoid the regex from interpreting\wand\sas alphabets:wands.
Also, we notice several words are part of HTML tags and not relevant to the data we require. Lets define a list called rogue_words to handle the same,
1 2 | |
Now we can extract the products as follows,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
1 | |
Now let's create a wordcloud function which will visually inform us about which products are more prominent than the others. The size of the word would indicate its frequency.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Creating wordclouds for products,
1 | |

What type of industries do the top 20 company belong from?¶
Similarly, looking at a sample for industry,
1 2 | |
1 2 3 4 5 | |
We can observe that we need to :
- Extract products from between [[ and ]]
- Split and seperate by the delimiter |
- Only keep alphanumeric characters, - and preserve spaces
Using the same regex and rogue_words to clean and extract the industries,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 | |
Just as before let's create a wordcloud for industry,
1 | |

What the assets of the top 20 companies look like?¶
Taking a look at a sample of assets below,
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
We would need to :
- Extract both numbers and the unit i.e.
billionortrillion - Keep only the monetary values (discard year)
We can also observe that the asset value always appears first and then the year follows.
Defining a simple regular expression for the same,
1 | |
Regex breakdown :
([\d\.]+): matches and captures one or more(+)numbers(0-9)with decimal(.).
1 | |
Regex breakdown :
(billion|trillion): matches and captures eitherbillionortrillion
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Since we have both billion as well as trillion, let's normalize all the values,
1 2 3 4 | |
And create a new dataframe from the same,
1 2 | |
| company | value | unit | |
|---|---|---|---|
| 0 | Walmart | 219.295 | billion |
| 1 | ExxonMobil | 346.2 | billion |
| 2 | Berkshire Hathaway | 707.8 | billion |
| 3 | Apple Inc. | 338.516 | billion |
| 4 | UnitedHealth Group | 173.889 | billion |
| 5 | McKesson Corporation | 60.381 | billion |
| 6 | CVS Health | 196.456 | billion |
| 7 | Amazon (company) | 162.648 | billion |
| 8 | AT&T | 531 | billion |
| 9 | General Motors | 227.339 | billion |
| 10 | Ford Motor Company | 256.54 | billion |
| 11 | AmerisourceBergen | 37.66 | billion |
| 12 | Chevron Corporation | 253.9 | billion |
| 13 | Cardinal Health | 39.95 | billion |
| 14 | Costco | 45.4 | billion |
| 15 | Verizon Communications | 264.82 | billion |
| 16 | Kroger | 38.11 | billion |
| 17 | General Electric | 309.129 | billion |
| 18 | Walgreens Boots Alliance | 67.59 | billion |
| 19 | JPMorgan Chase | 2687 | billion |
Now finally let's create a bar plot showcasing the assets from all the companies,
1 2 3 4 5 6 7 8 9 10 11 12 | |
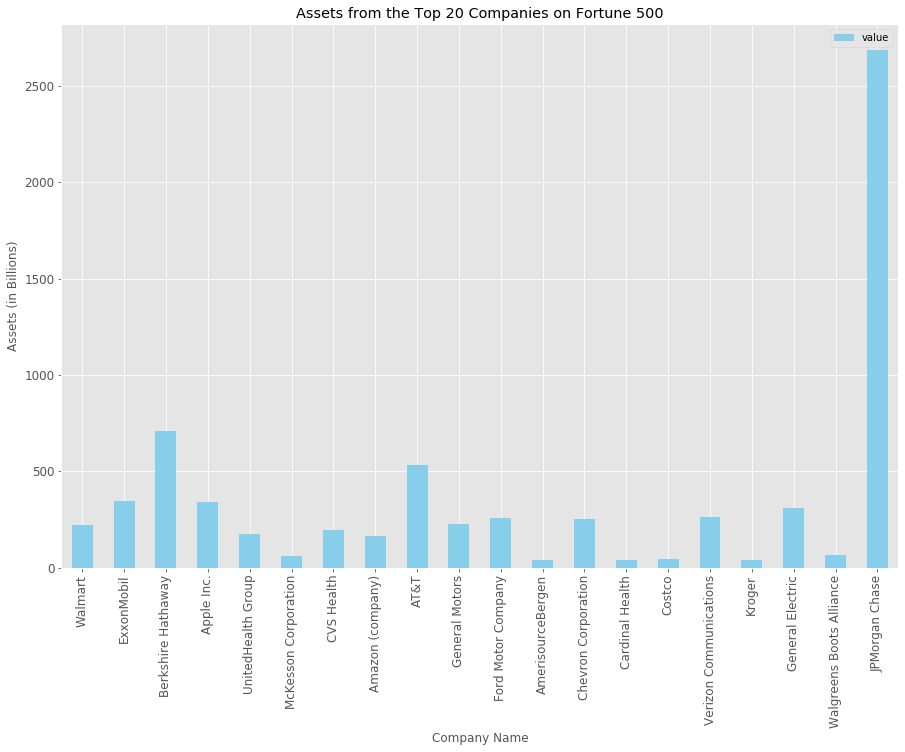
Now let's create a new dataframe containing data related to products, industry and assets as follows,
1 2 | |
| wiki_title | product | industry | assets | |
|---|---|---|---|---|
| 0 | Walmart | pet supplies, party supplies, clothing, footwear, photo finishing, fitness, auto, grocery, electronics, home, movies, sporting goods, toys, beauty, jewelry, craft supplies, home improvement, music, furniture, health | retail | 219.295 billion |
| 1 | ExxonMobil | petrochemicals, crude oil, oil products, natural gas, power generation | gas, energy, oil, energy industry, gas industry | 346.2 billion |
| 2 | Berkshire Hathaway | food processing, casualty insurance, property, mass media, media, aerospace, insurance, final good, utilities, real estate, automotive industry, consumer products, internet, public utility, restaurants, sports equipment, sporting goods, toys, types, diversified investments, investment, automotive | company, conglomerate | 707.8 billion |
| 3 | Apple Inc. | siri, iphone, watchos, tvos, shazam, ilife, iwork, final cut pro, ipod, application, apple watch, ipad, logic pro, macintosh, homepod, apple tv, macos, garageband, ios, ipados | fabless manufacturing, cloud computing, semiconductors, artificial intelligence, fabless silicon design, consumer electronics, computer software, financial technology, digital distribution, computer hardware | 338.516 billion |
| 4 | UnitedHealth Group | health care, uniprise, service, specialized care services, ingenix, economics, services | managed health care | 173.889 billion |
And finally let's combine the datasets from Section 2 and 3 as follows,
1 2 3 4 | |
1 | |
1 2 3 | |
| rank | company_name | company_website | wiki_title | product | industry | assets | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Walmart | http://www.stock.walmart.com | Walmart | beauty, footwear, furniture, party supplies, auto, fitness, pet supplies, movies, electronics, jewelry, craft supplies, clothing, grocery, music, photo finishing, home improvement, home, toys, sporting goods, health | retail | 219.295 billion |
| 1 | 2 | Exxon Mobil | http://www.exxonmobil.com | ExxonMobil | oil products, petrochemicals, crude oil, power generation, natural gas | gas industry, gas, energy, energy industry, oil | 346.2 billion |
| 2 | 3 | Berkshire Hathaway | http://www.berkshirehathaway.com | Berkshire Hathaway | diversified investments, mass media, automotive industry, media, final good, internet, food processing, public utility, sports equipment, insurance, investment, restaurants, casualty insurance, real estate, types, aerospace, automotive, consumer products, property, utilities, toys, sporting goods | conglomerate, company | 707.8 billion |
| 3 | 4 | Apple | http://www.apple.com | Apple Inc. | ipad, apple tv, ilife, application, ipados, siri, ios, shazam, iwork, ipod, homepod, macintosh, tvos, logic pro, garageband, watchos, apple watch, macos, iphone, final cut pro | artificial intelligence, cloud computing, digital distribution, computer software, financial technology, computer hardware, semiconductors, consumer electronics, fabless manufacturing, fabless silicon design | 338.516 billion |
| 4 | 5 | UnitedHealth Group | http://www.unitedhealthgroup.com | UnitedHealth Group | ingenix, service, specialized care services, uniprise, health care, economics, services | managed health care | 173.889 billion |
| 5 | 6 | McKesson | http://www.mckesson.com | McKesson Corporation | pharmaceuticals, medical technology, health care services | healthcare | 60.381 billion |
| 6 | 7 | CVS Health | http://www.cvshealth.com | CVS Health | health care, retail | 196.456 billion | |
| 7 | 8 | Amazon.com | http://www.amazon.com | Amazon (company) | amazon fire os, fire os, amazon fire tablet, amazon kindle, amazon fire tv, amazon fire, amazon echo | artificial intelligence, e-commerce, cloud computing, digital distribution, consumer electronics, grocery stores | 162.648 billion |
| 8 | 9 | AT&T | http://www.att.com | AT&T | film production, sports management, video games, landline, podcasts, publishing, pay television, satellite television, television production, internet service provider, network security, iptv, cable television, fixed-line telephones, ott services, mobile telephones, internet services, digital television, mobile phone, news agency, home security, over-the-top media services, broadband, filmmaking | technology, entertainment, mass media, technology company, telecommunications industry, telecommunications | 531.0 billion |
| 9 | 10 | General Motors | http://www.gm.com | General Motors | automobiles, car, automobile parts, commercial vehicles | automotive, automotive industry | 227.339 billion |
| 10 | 11 | Ford Motor | http://www.corporate.ford.com | Ford Motor Company | automobiles, automotive parts, pickup trucks, car, luxury car, commercial vehicles, list of auto parts, suvs, luxury vehicles, commercial vehicle | automotive, automotive industry | 256.54 billion |
| 11 | 12 | AmerisourceBergen | http://www.amerisourcebergen.com | AmerisourceBergen | pharmacy services, pharmaceuticals | pharmaceutical | 37.66 billion |
| 12 | 13 | Chevron | http://www.chevron.com | Chevron Corporation | other, see chevron products, petrochemicals, marketing brands, petroleum, natural gas | gas, gas industry, oil | 253.9 billion |
| 13 | 14 | Cardinal Health | http://www.cardinalhealth.com | Cardinal Health | pharmaceutical products, medical, services | pharmaceuticals | 39.95 billion |
| 14 | 15 | Costco | http://www.costco.com | Costco | retail | 45.4 billion | |
| 15 | 16 | Verizon | http://www.verizon.com | Verizon Communications | mobile phone, iptv, telematics, internet, cable television, broadband, internet of things, landline, digital media, digital television | telecommunications industry, telecommunications, mass media | 264.82 billion |
| 16 | 17 | Kroger | http://www.thekrogerco.com | Kroger | superstore, other specialty, supermarket, supercenter | retail | 38.11 billion |
| 17 | 18 | General Electric | http://www.ge.com | General Electric | lighting, finance, wind turbines, electrical distribution, software, aircraft engines, energy, health care, electric power distribution, electric motors | conglomerate, company | 309.129 billion |
| 18 | 19 | Walgreens Boots Alliance | http://www.walgreensbootsalliance.com | Walgreens Boots Alliance | drug store, pharmacy | pharmaceutical, retail | 67.59 billion |
| 19 | 20 | JPMorgan Chase | http://www.jpmorganchase.com | JPMorgan Chase | broker services, finance, institutional investing, trustee services, currency exchange, debt settlement, financial markets, venture capital, foreign exchange market, loan servicing, mortgage brokers, index funds, investment banking, hedge funds, exchange-traded funds, mortgage-backed security, mortgage, mutual funds, underwriting, stock trading, security, investment management, prime brokerage, mortgage brokering, retail banking, backed securities, mortgage loans, bond, digital banking, merchant services, money market trading, american depositary receipts, financial analysis, credit cards, institutional investor, private equity, commodity market, insurance, capital market services, investment, retail, mobile banking, treasury services, alternative financial services, futures exchange, private banking, portfolios, subprime lending, bond trading, financial capital, custodian banking, commodities trading, risk management, pension funds, estate planning, brokerage, collateralized debt obligations, portfolio, asset management, securities lending, wholesale mortgage lenders, credit default swap, wealth management, remittance, wholesale mortgage lending, wire transfers, investment capital, credit derivative trading, information processing, security services, stock trader, asset allocation, wholesale funding, commercial banking | financial services, banking | 2.687 trillion |
And export them to a csv file,
1 | |
Challenge¶
Create a bar chart of equity of all the top 20 Fortune 500 companies and find out which has the highest value.