API based scraping
![]()
A brief introduction to APIs¶
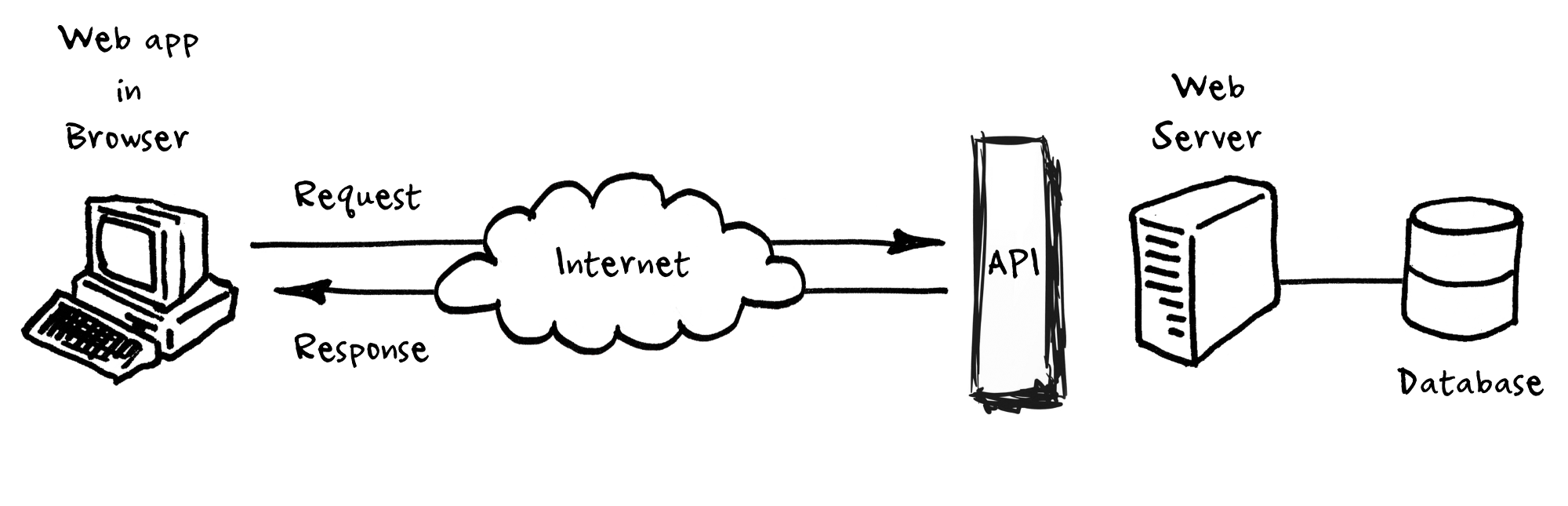
In this section, we will take a look at an alternative way to gather data than the previous pattern based HTML scraping. Sometimes websites offer an API (or Application Programming Interface) as a service which provides a high level interface to directly retrieve data from their repositories or databases at the backend.
From Wikipedia,
"An API is typically defined as a set of specifications, such as Hypertext Transfer Protocol (HTTP) request messages, along with a definition of the structure of response messages, usually in an Extensible Markup Language (XML) or JavaScript Object Notation (JSON) format."
They typically tend to be URL endpoints (to be fired as requests) that need to be modified based on our requirements (what we desire in the response body) which then returns some a payload (data) within the response, formatted as either JSON, XML or HTML.
A popular web architecture style called REST (or representational state transfer) allows users to interact with web services via GET and POST calls (two most commonly used) which we briefly saw in the previous section.
For example, Twitter's REST API allows developers to access core Twitter data and the Search API provides methods for developers to interact with Twitter Search and trends data.
There are primarily two ways to use APIs :
- Through the command terminal using URL endpoints, or
- Through programming language specific wrappers
For example, Tweepy is a famous python wrapper for Twitter API whereas twurl is a command line interface (CLI) tool but both can achieve the same outcomes.
Here we focus on the latter approach and will use a Python library (a wrapper) called wptools based around the original MediaWiki API.
One advantage of using official APIs is that they are usually compliant of the terms of service (ToS) of a particular service that researchers are looking to gather data from. However, third-party libraries or packages which claim to provide more throughput than the official APIs (rate limits, number of requests/sec) generally operate in a gray area as they tend to violate ToS. Always be sure to read their documentation throughly.
Wikipedia API¶
Let's say we want to gather some additional data about the Fortune 500 companies and since wikipedia is a rich source for data we decide to use the MediaWiki API to scrape this data. One very good place to start would be to look at the infoboxes (as wikipedia defines them) of articles corresponsing to each company on the list. They essentially contain a wealth of metadata about a particular entity the article belongs to which in our case is a company.
For e.g. consider the wikipedia article for Walmart (https://en.wikipedia.org/wiki/Walmart) which includes the following infobox :
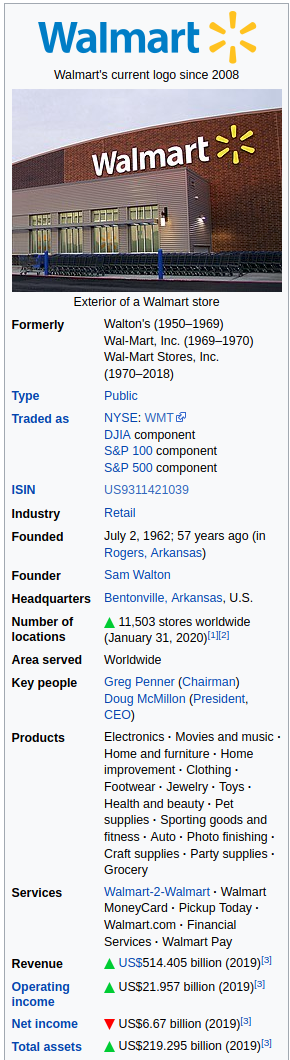
As we can see from above, the infoboxes could provide us with a lot of valuable information such as :
- Year of founding
- Industry
- Founder(s)
- Products
- Services
- Operating income
- Net income
- Total assets
- Total equity
- Number of employees etc
Although we expect this data to be fairly organized, it would require some post-processing which we will tackle in our next section. We pick a subset of our data and focus only on the top 20 of the Fortune 500 from the full list.
Let's begin by installing some of libraries we will use for this excercise as follows,
1 2 3 4 | |
Importing the same,
1 2 3 4 5 6 | |
1 | |
Now let's load the data which we scrapped in the previous section as follows,
1 2 3 4 | |
1 | |
1 2 3 | |
| rank | company_name | company_website | |
|---|---|---|---|
| 0 | 1 | Walmart | http://www.stock.walmart.com |
| 1 | 2 | Exxon Mobil | http://www.exxonmobil.com |
| 2 | 3 | Berkshire Hathaway | http://www.berkshirehathaway.com |
| 3 | 4 | Apple | http://www.apple.com |
| 4 | 5 | UnitedHealth Group | http://www.unitedhealthgroup.com |
Let's focus and select only the top 20 companies from the list as follows,
1 2 3 | |
Taking a brief look at the same,
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Getting article names from wiki¶
Right off the bat, as you might have guessed, one issue with matching the top 20 Fortune 500 companies to their wikipedia article names is that both of them would not be exactly the same i.e. they match character for character. There will be slight variation in their names.
To overcome this problem and ensure that we have all the company names and its corresponding wikipedia article, we will use the wikipedia package to get suggestions for the company names and their equivalent in wikipedia.
1 | |
Inspecting the same,
1 2 3 4 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | |
Now let's get the most probable ones (the first suggestion) for each of the first 20 companies on the Fortune 500 list,
1 2 3 4 | |
1 | |
We can notice that most of the wiki article titles make sense. However, Apple is quite ambiguous in this regard as it can indicate the fruit as well as the company. However we can see that the second suggestion returned by was Apple Inc.. Hence, we can manually replace it with Apple Inc. as follows,
1 2 | |
1 | |
Retrieving the infoboxes¶
Now that we have mapped the names of the companies to their corresponding wikipedia article let's retrieve the infobox data from those pages.
wptools provides easy to use methods to directly call the MediaWiki API on our behalf and get us all the wikipedia data. Let's try retrieving data for Walmart as follows,
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
As we can see from the output above, wptools successfully retrieved the wikipedia and wikidata corresponding to the query Walmart. Now inspecting the fetched attributes,
1 | |
1 | |
The attribute infobox contains the data we require,
1 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
Let's define a list of features that we want from the infoboxes as follows,
1 2 3 4 | |
Now fetching the data for all the companies (this may take a while),
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 | |
Let's take a look at the first instance in wiki_data i.e. Walmart,
1 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
So, we have successfully retrieved all the infobox data for the companies. Also we can notice that some additional wrangling and cleaning is required which we will perform in the next section.
Finally, let's export the scraped infoboxes as a single JSON file to a convenient location as follows,
1 2 | |
References¶
- https://phpenthusiast.com/blog/what-is-rest-api
- https://github.com/siznax/wptools/wiki/Data-captured
- https://en.wikipedia.org/w/api.php
- https://wikipedia.readthedocs.io/en/latest/code.html